Execute a K-nearest neighbors classification method on the data. What model specification returned the most accurate results? Did adding a distance weight help?
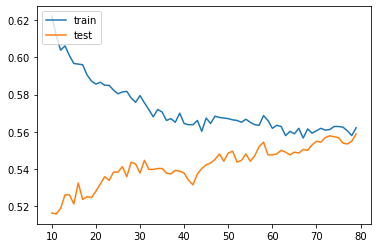
The best score was 56% using 77 neighbors, but as the number of neighbors increased the training data score decresed to match more closely the testing data score. WHle this bodes not so well for the ability of our model to predict and outcome, it does indicate that the data is not overfit.
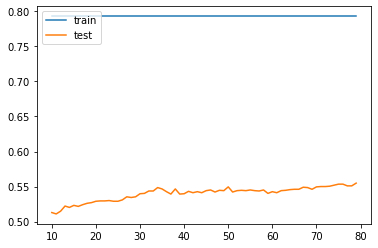
Adding distance as weight did not improve the score, it actually decreased the score from 56 to 55% as its max value at 79 neighbors. However, in this model the training data did consistently better than the testing data, rather than decreasing like it did in the unweighted model. This may indicate that using weights results in an overfit model as while it does well predicting the target usign the trainig data, it does rather poorly on the testing data
Execute a logistic regression method on the data. How did this model fair in terms of accuracy compared to K-nearest neighbors?
Logistic regression did not perform better than the K-nearest neighbors model, in fact it performed worse with an accuracy of 53%.
Next execute a random forest model and produce the results. See the number of estimators (trees) to 100, 500, 1000 and 5000 and determine which specification is most likely to return the best model. Also test the minimum number of samples required to split an internal node with a range of values. Also produce results for your four different estimator values by both comparing both standardized and non-standardized (raw) results.
Raw data for random forest model
| n | Training Score | Testing Score |
|---|---|---|
| 100 | 0.7939453125 | 0.46168862859931675 |
| 500 | 0.7939453125 | 0.46168862859931675 |
| 1000 | 0.7939453125 | 0.46168862859931675 |
| 5000 | 0.7939453125 | 0.46168862859931675 |
Standardized data for random forest model
| n | Training Score | Testing Score |
|---|---|---|
| 100 | 0.799153645833 | 0.4899951195705222 |
| 500 | 0.799153645833 | 0.4899951195705222 |
| 1000 | 0.799153645833 | 0.49194729136163984 |
| 5000 | ** |
** I had to interrupt the kernel for this random forest model becuase the run time was much too long. The time limit I set was about 30 minutes, and even after that length of time the test still hadn’t finished running.
Repeat the previous steps after recoding the wealth classes 2 and 3 into a single outcome. Do any of your models improve? Are you able to explain why your results have changed?
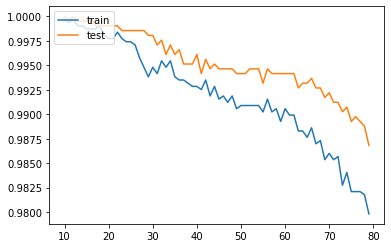
Once the wealth 2 and 3 categories were merged, every model did extremely better. All classification models scored close to 100% acurracy at 10 neighbors.
Non Weighted KNN
Weighted KNN
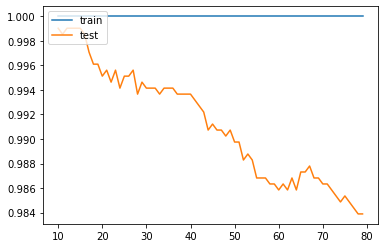
I believe the model did much better in this case becuase the number of categories it had to sort data into was smaller, this gave the model a much lower chance of being incorrect as there were only 3 categories instead of 4. This means the model had a 33% chance of being correct, which is pretty high. Not only so, but the model does not have to sort between wealth 2 and wealth 3, which are categories that would otherwise may be very similar.